|
■■■記載日2011年01月21日■■■08:00頃記載 【μ-iVoiceについて】 μ-iVoiceは、現状のブラウザでプラグインなしにJavaScriptだけで動作させることを想定したコンパクトな音声合成エンジンです。 現在、Version 0.09Cのμ-iVoiceを公開中です。 対象ブラウザは、Google Chrome, Mozilla Fire Fox, Apple Safariになります。 Text-To-Speech API(テキスト読み上げAPI)ですが、抑揚コントロールのための簡易なスクリプトを実装しています。 さらに、元がシンセサイザーなので、シンセサイザー演奏モードと簡易ボカロの機能があります。 ローカルに音声データファイルを用意すれば、ドラッグドロップで組込が行えるので、任意の話者で発声が可能です。 レンダリング速度を重視した結果、音声合成アルゴリズムは、変形DDS (Direct Digital Synthesizser)を用いることにしました。 HTML5で導入されたaudioタグのソースにBase64形式のData URIを与えて、Data Schemeを使って再生を行っています。 IEは、.wav形式のData Schemeに対応していないようなので使えません。 波形レンダリング・アルゴリズムをMPEGに対応させれば、解決するのでしょうが、 まだMPEGエンコーダを自力コーディングする能力が不足しているのと、 ブラウザ側の処理能力も低いので、Native Clientが標準実装される頃に再考してみたいと思います。 μ-iVoiceは、JavaScriptだけで記述されているので、『ソースを表示』すればソース閲覧が可能です。 このページではその他の詳細情報をメモしておきます。(私はすぐに忘れるので.....) |
|
【μ-iVoice】『Webで使える音声合成/シンセサイザAPI』μ-iVoiceは私設研究所Neo-Tech-Lab.com特製の音声合成APIです。現在、Version0.09Cです。0.5秒スパン、135音の音声データ(モノラル, 16bit, 22.050kHz)を使って発声を行います。 但し、ソースは子音等の扱いに関して処理をはしょったレンダリング速度最優先の音質劣化バージョンとさせていただいています。是非、本家Ⅱのレンダリング速度とJavaScript DDS方式を比べてみて下さい。 初回のアクセスは少しお待ちいただく必要があります。 スタートまでの時間がかかるのは、90秒分のメッセージと2分21秒分のシンセサイザー演奏デモのレンダリングを行っているためです。デモの初期化部分を外せば短時間で立ち上がります。 (自分の声はいくらエディットしてもなんか癖を感じ、やっぱりキモイのでアップしませんが。) 音声データ記録ツール(Excel VBA)を使って音声データの作成・編集を行うことができます。 音声データの交換により、任意話者による発声を行うことができます。 将来目標は、『あいうえお』の5音登録だけで任意話者に対応することです。 現在のところ、ひらがなのみ発声可能です。漢字⇒かな変換は開発中です。文字数の制約はありません。 簡単な半角英数字のスクリプトによる制御コードを挟めば、アクセントやイントネーション、歌唱が可能です。自動抑揚付与も開発中です。 発声原理は、変形DDS(Direct Digital Synthesizer)アルゴリズムを用いています。 今後は、波形レンダリング処理にもう少し手を加えて、音質の向上を行います。 【サイト埋め込み方法の例】 【1】 <iframe border="0" src="http://www.geocities.jp/ivoiceapi/index.htm" width=720px height="1150px"></iframe> 【2】 <iframe border="0" src="http://neotechlab.web.fc2.com/index.htm" width=800px height="1200px"></iframe> |
|
【Version0.09までの実装機能履歴】【第1次試作】/2011/08/09/~/2011/08/12/【Version0.01】/2011/08/09/ ●DDS(Direct Digital Synthesizer)によるMIDIデータ演奏(ステレオ,16bit,44.1kHz) 【Version0.02】/2011/08/09/ ●アタック、消退 【Version0.03】/2011/08/10/ ●ドラムパートの追加 【Version0.04】/2011/08/10/ ●内部データ形式の変更と1秒単位の波形レンダリングに変更 【Version0.05】/2011/08/12/ ●音声パートの追加 【Version0.06】/2011/08/12/ ●スピーチ機能の追加 【第2次試作】/2011/12/29/~/2012/01/19/ 【Version0.07】/2012/01/02/ ▼ブラウザ改訂の悪影響で1MBを超えるBase64⇒Binaryに問題が発生したので、これを解決。 ●音声データ及びドラムデータを疑似JSONPからBase64形式.wavファイルに変更 ●ステレオ, 16bit, 44.1kHz⇒モノラル, 16bit, 22.05kHz(読込速度の問題で劣化) ●抑揚(音階、長さ、強さ)を制御するScriptを実装 【Version0.08】/2012/01/10/ ●音声データのレンダリング方式の変更(1000倍の時間分解能でスムージング) ●ローカルの.wav形式音声データファイルをセレクトあるいはドラッグドロップでNTL_Voiceに組込み可能 録音ツールで録音・編集した音声データを使って任意話者での音声合成を行うことができます。 ●応答メッセージ読み上げ機能 【Version0.09】/2012/01/15/ ●カナ、漢字や数字の音読み、訓読み機能の追加 (膨大な量のデータベース構築が必要なので小学校レベルで徐々に拡充の予定) 熟語については今後対応の予定 ●漢字辞書に読み替えひらがなを登録しているが、制御スクリプトも書き込めるので抑揚自動付与が可能 【開発中の機能】【第3次試作】/2012/01/20/~■子音と母音の抽出速度制御 ■任意話者の『あいうえお』の5音のサンプル音だけからの物真似発声(ターミネーター音声ハック機能) 【μ-iVoice開発予定】【Version1.0】/2012/06/14/~漸くμ-iVoice Version1.0の女性ナレーターが内定しそう。 音声チャット会議でオリジナル・キャラ(PMDモデル)と合わせて開発開始という事になった。 モデル案はリアルとバーチャルの2案があるのでどちらに決まるかはわからないが、 キャラ設定は次回リアル会議で決定の予定。 |
|
【シンセサイザの各音階の周波数の設定について】■■■記載日2012年1月13日■■■23:58頃記載シンセサイザの各音階の周波数は 1) 基準となる周波数はA4[ラ]で440Hzである。 2) 12平均律(右隣の半音は2^(1/12)=1.0594630943593倍の周波数である。)を使う。 の2点だけを知っていれば簡単に求めることができる。 下表は、Excelで計算した各音階の周波数リストである。 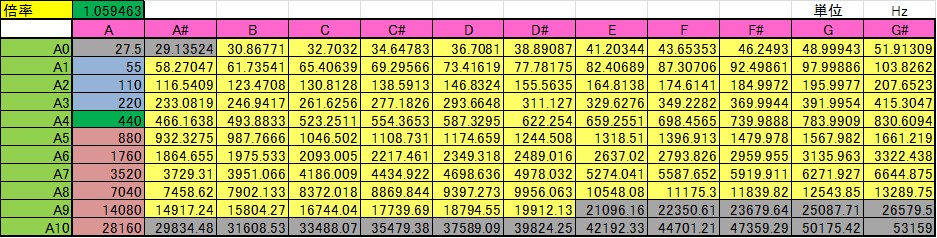 |
【どうして別人の物真似ができるのか?:標準子音と任意母音の合成】■■■記載日2012年1月14日■■■02:45頃記載どうして、ものまね芸人は他人の声をうまくまねることができるのか考えてみた。 『子音はきっと誰の声でもそんなに差異がないのでは?』あるいは『子音は広帯域スペクトルなので特徴認識しにくいのでは?』との考えに至った。 MikuMikuDanceの作者、樋口優さんのホームページにある優れものツール『MikuMikuVoice』(1.5 なんちゃってツール)を使って、自分の音声と初音ミクの音声について、幾つかの子音部分だけを聴き比べてみたら、やはり区別することはできなかった。 私の耳で確認した範囲では、子音には音の高低を判断できる成分(線スペクトル)が含まれていないように思われる。子音だけでは男女の区別もつかないようだ。 それではと考え、私の『か』の音の子音部分の後ろに初音ミクの『あ』の音を接続して聞いてみたところ、ちゃんと初音ミクが『か』と発音しているように聞き取れるではないか。 人間の聴力では、細かな差異は認識しにくく、線スペクトルの何本かの特徴で人の声を聞き分けているのだろう。 だから、予め、Aさんの子音のデータベースを作り、Bさんの『あ』『い』『う』『え』『お』の5音の声で合成すれば、Bさんの声に聞こえるはずだ。 多分、任意の話者Bさんの『あ』『い』『う』『え』『お』の5音を採録するだけで、ほぼBさんそっくりの声が出せるはずだ。 普段の会話の一部でも録音できれば、母音を5音とも抽出することができる。映画のターミネーターのように他人の声をハックすることができるわけだ。 これは相当な工数削減が望めそうだし、データ圧縮が期待できる。 加えて、母音の音声データだけなら、2.5次元FDTDによる解析ができ、MRIスライスデータがあれば演算で求めることもできる。 つまり3次元人体構造が判明していれば、その人物の声を聴かずに、声を再現することができるわけだ。 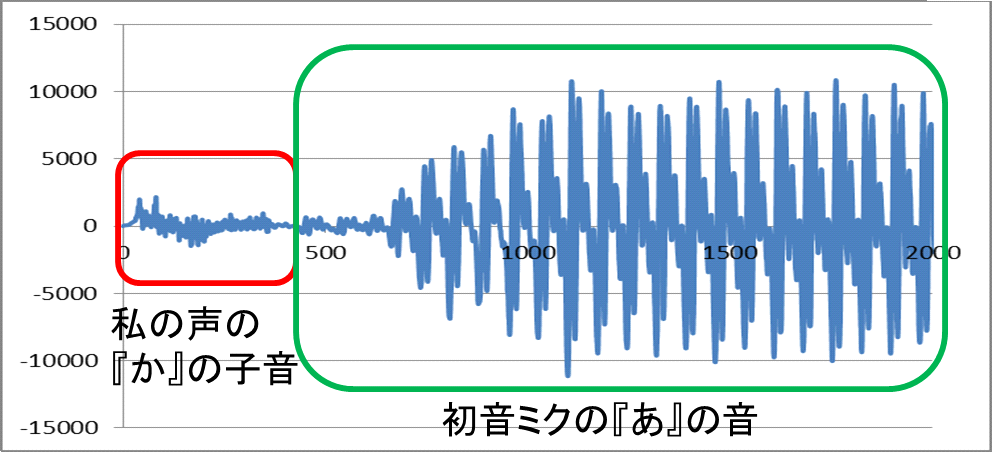 【図】子音と母音の合成 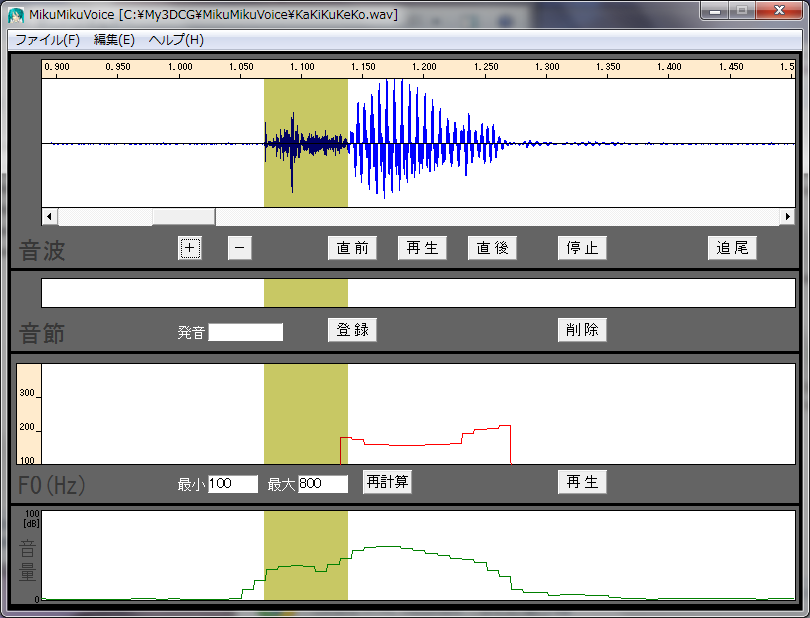 【図】MikuMikuVoiceによる選択部分の再生 44.1kHz, 16bitの.wav形式ファイルが読み込める。+ボタンで拡大ができ、マウスドラッグで領域選択した部分を『再生』で聞き取ることができる。 |
【子音、母音と音階の関係について】■■■記載日2012年1月14日■■■22:37頃記載子音は一般に広帯域スペクトルを持った過渡応答波形であるので、線スペクトルを殆ど有していない。 このため、音階として認識されるのは、母音の成分の方であるはずだ。 実際に、『か』でドレミファソラシドを発声してみた。 MikuMikuVoiceで子音の部分だけを聞いてみたが、やはり音階は持たなかった。 従って、過渡応答波形である子音部分は音階によらず、録音時のサンプリングレートで再生し、 母音だけを音階に対応した周波数で再生すればよいことがわかる。 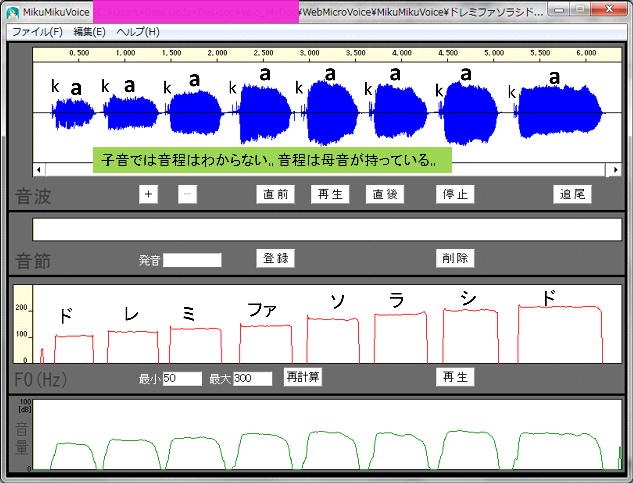 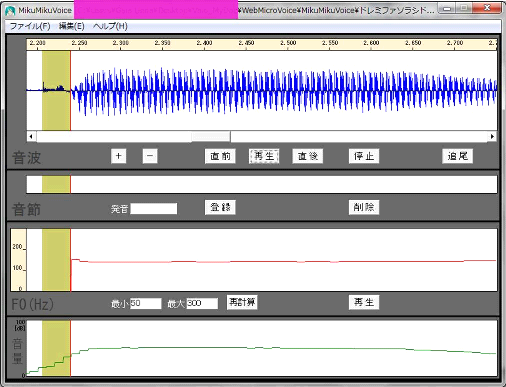 |
【音声データ補間法について】■■■記載日2012年1月18日■■■21:50頃記載既に20年以上前の技術なので記載しておく。 音声データのサンプリング速度は、Version0.006で44.1kHz、Version0.007~0.009で22.05kHzである。 DDS (Direct Digital Synthesizer)では、この音声データが再生周波数で決まる時間幅で読みだされる。 再生周波数がサンプリング周波数に近ければそれほど問題は生じないが、 周波数が低いと、同じデータが複数回連続して読み出され、周波数が高いと、間が飛んでしまう。 つまり、時刻分解能が劣化してしまうので、音質劣化につながる。 これを回避するために、サンプリング関数(sinx/x)による補間と直線補間を組み合わせた方法を採用している。 1968年に出版された電気学会の『測定値の統計処理』にサンプリング関数による補間法が記載されている。 採用方法では、4つのサンプル(w0,w1,w2,w3)を使い、両端の2点(w0,w3)を使って直線補間を行う。 中央2個のサンプル位置での直線補間値をw1とw2から取り除き、残りの量に対してサンプリング補間を行う。 サンプリング関数は最初に1000倍程度の時間分解能で求めておけば、テーブル参照だけで補間を行うことができる。 参考までにExcel VBAでのコーディング例を示す。 補間処理実行時には、加減算と乗算だけで曲線補間を行うことができる。 この方法は非常に便利で、ノイズ除去やサンプリング速度変換等、様々な応用が可能だ。 3Dグラフィックスの場合には、Phong Shading等でベクトル補間の演算負荷を圧縮することができる。 波形データの場合にはデータ圧縮などにも応用が可能だ。 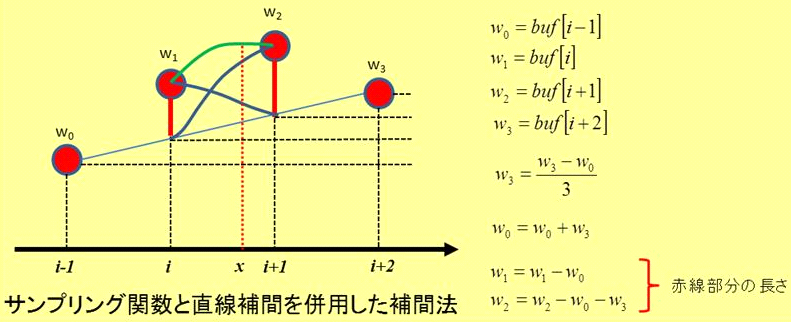 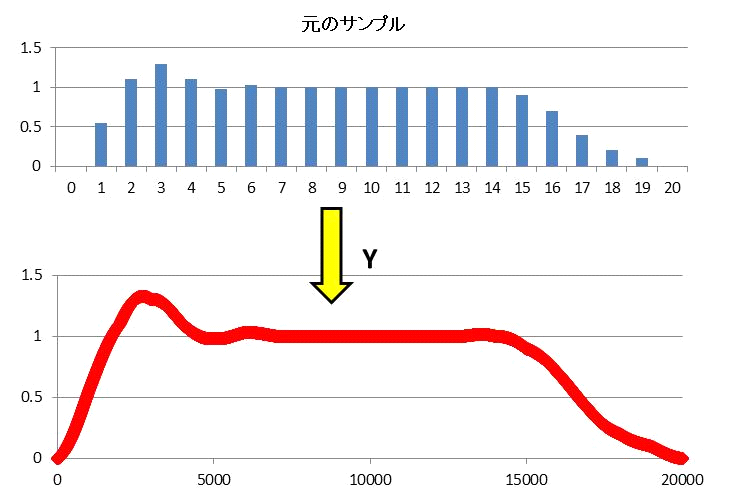 |
【Excel VBAの場合】
Public Iwave() As Single '【サンプリング関数】0~π
Public Const nIwave As Long = 1000 '【補間配列の個数】サンプル間の分割数 実際のサイズはnIwave+1
Public w0, w1, w2, w3, w4, w5, w6 As Single 'w4:1/3 w5:nIwave w6:1/nIwave
'************************************************
'【CreateConstants】補間係数テーブル作成【Version0.08】+α
'************************************************
'●DDS劣化現象低減の為、補間演算で、より滑らかなデータを発生する
Public Sub CreateConstants()
Dim Pi As Single, a As Single, x As Single, i As Long
ReDim Iwave(nIwave)
Pi = Atn(1#) * 4#
a = Pi / nIwave
Iwave(0) = 1#
For i = 1 To nIwave
x = i * a
Iwave(i) = Sin(x) / x
Next i
w4 = 1# / 3#
w5 = CSng(nIwave)
w6 = 1# / nIwave
End Sub
'************************************************
'【CreateConstants】簡易曲線補間演算【Version0.08】+α
'************************************************
'●平成元年頃に産総研(当時は電子技術総合研究所)の基礎計測部 計測基礎研究室の
'葛西直子主任研究官が上田の特許2071969に関して改善提案された補間方法に基づく。
'ここでは4サンプル値(y0,y1,y2,y3)からy1~y2間の補間値を得る。
Public Function CalculationValue(ByRef buf() As Single, n As Long, x As Single) As Single
' buf(): 補間対象のデータ配列 n:配列要素数 x:小数点以下を補間
Dim i, j As Long
i = Int(x) '小数点以下を切り捨てて整数化
'4サンプルを取得 w0, w1, w2, w3
If i > 0 Then w0 = buf(i - 1) Else w0 = 0#
w1 = buf(i)
If (i + 1) < n Then w2 = buf(i + 1) Else w2 = 0#
If (i + 2) < n Then w3 = buf(i + 2) Else w3 = 0#
'補間処理
i = Int((x - CSng(i)) * w5) 'xの小数点以下を補間関数のレンジにマッピング
j = nIwave - i
w3 = (w3 - w0) * w4
w0 = w0 + w3
w1 = w1 - w0
w2 = w2 - w0 - w3
w3 = w3 * w6
CalculationValue = w0 + CSng(i) * w3 + w1 * Iwave(i) + w2 * Iwave(j)
End Function
|
【音声データ補間法について その2】データ圧縮■■■記載日2012年1月21日■■■06:57頃記載試に上記アルゴリズムを使ってデータ圧縮を試みた。 『あ』と『え』と『か』の変換結果を下に示す。 115200bpsというのは、8bitのデータを11.52kHzで非同期シリアル通信で伝送することを想定している。 圧縮後の結果を見る限り、ホームコンピュータ側で音声合成処理をかけた後で、 ZigBee(無線通信インターフェース)でサイボーグインターフェースまでデータを送信するのには十分使えそうだ。 母音は高周波成分を殆ど含まないから簡単だ。 ターミネーター音声ハックには十分使えそうに思える。 『か』の子音部分では流石にデータの劣化が見て取れる。まあなんとか使える範囲か? 子音の圧縮率は抑えて、時間の大半を占める母音部分の圧縮率を高めれば1/30位のデータ圧縮は届きそうに思える。 音声フォルマント周期を拾うエンコーダに手を出すべきか? 迷うところだ。 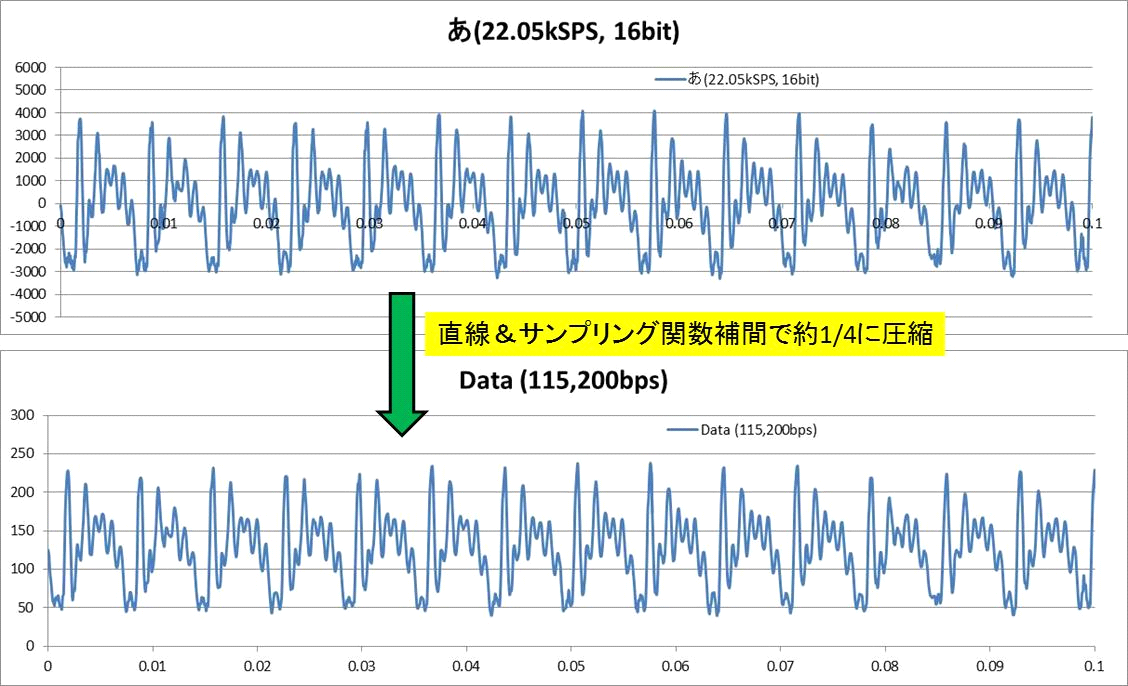 ←『あ』の変換結果 ←『あ』の変換結果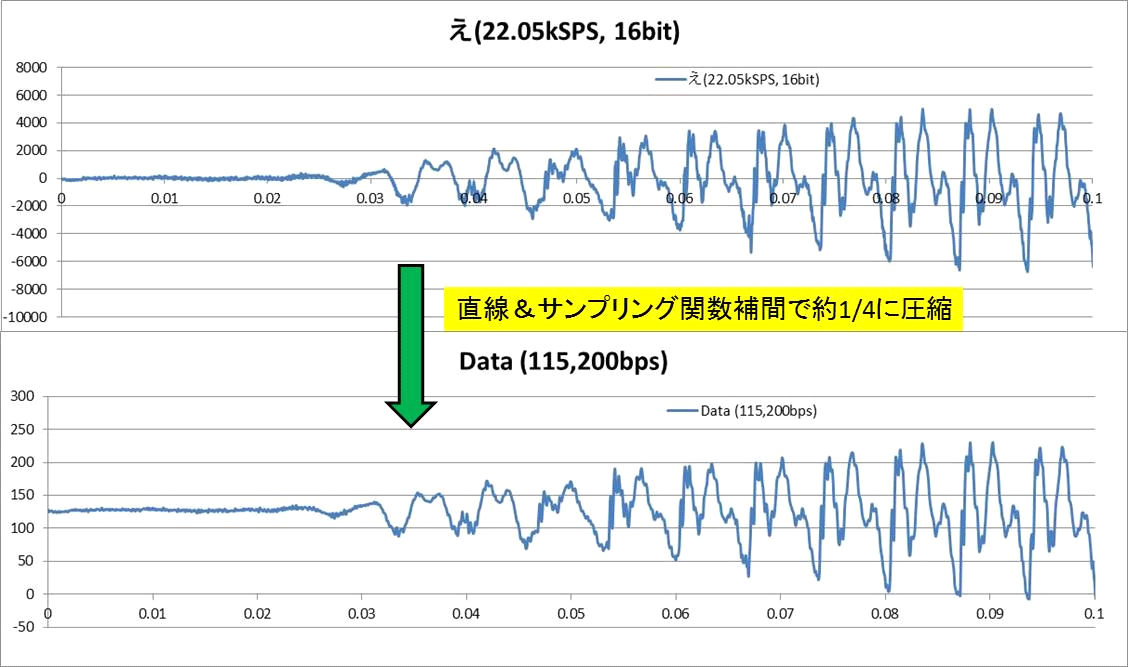 ←『え』の変換結果 ←『え』の変換結果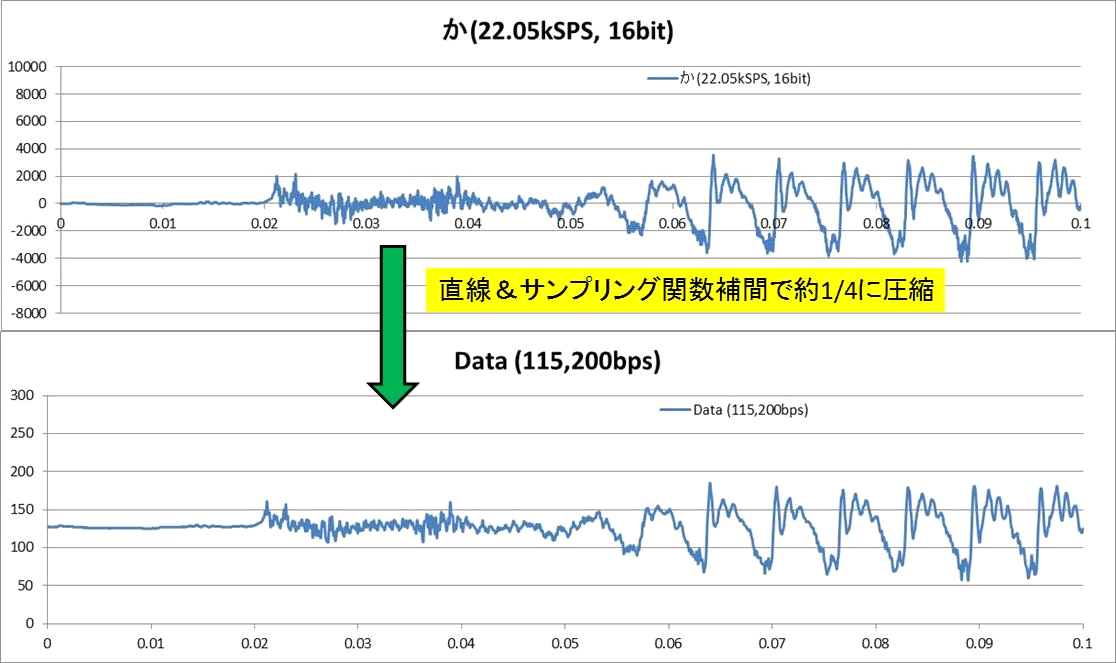 ←『か』の変換結果 ←『か』の変換結果 |
【現状の問題点について】■■■記載日2012年1月16日■■■00:47頃記載Version0.09でローカル音声データの組み込みを試したところ、うまく機能した。但し、以下の点が課題として残る。 1.子音の長さと音階を揃えて録音しないと、少し違和感のある発声になる。 2.母音だけを周期音扱いして子音をドラムと同じ過渡音としていないので、音域が狭い。 3.ブラウザ側の制約で、音声データサイズが少し大きい。 処理速度的にはデータ転送量を1/8程度に落とす事が好ましい。 4.漢字ボキャブラリが少ない。(今後拡充予定) 5."ー"(長音記号)に対応させる必要性 6.な行、ま行と'ん'については課題が残るが、ターミネータ音声ハックの子音/母音ブレンド機能の追加  子音先頭への位置合わせも自動化したいところ |
|
■■■記載日2011年8月9日■■■23:54頃記載 【Web シンセサイザ/ボーカロイドを一から製作してみよう】 Vocaloid2エディタをインストールしていたノートパソコンが壊れたので、 別のパソコンにインストールしようとしたらインストールできない。 (LANに接続しているのに『接続できない』とメッセージが出てそのせいかアクティベートできない!) 頭にきたので、シンセサイザとボーカロイド(正確には真似ロイド)を一から製作してみようと思い立つ。 JavaScriptだけでブラウザ上で音を合成し、再生できるように考えてみた。 前からMIDIコンポーザとVocaloid2エディタの往復はとても不便だった。どうせなら機能を統合してみよう。★ (かなり飽きっぽい性格なので、どうせ途中で飽きるだろうけど。) 取り敢えず、Google Chrome12, Mozilla FireFox5, Apple Safari5.1で動作するシンセサイザのコアを製作してみた。 FireFox5以外で動作することからわかるようにAudio出力API (audioタグの事ではない。) は使っていない。 【追記】DirectXのDirectSoundをブラウザから使えるようにしたらしいWeb Audioと言うのも使っていない。 今回はシンセサイザをハードウェア(CPLD)設計技術の一つであるDDS(Direct Digital Synthesizer)で構成してみたら、 思ったより短いコードで済んだ。あっさり動作した。こんなに簡単だとは思わなかった。 【Web MIDI】 ●【Finland民謡】『Ieavan Polkka』 (スタンダード・ドラム・セット使用) 波形データを演算(rendering)して、音が出るまで10秒~20秒程かかります。 まさかこんなにシンセサイザを作るのが簡単だとは思わなかったので、少しやる気が出たかも。 で、次はボーカロイドの方に着手。どうせなら、喋りと歌の両方ができるのを作ってみたい。 ただし、7月30日の記事で書いたYouTube動画の学習型発話器をソフトウェアで実行させる方式だ。 ミクの音源データを学習させて、ミクっぽい声を出させてみたい。 |
★将来的には、3次元立体音響ホロフォニクス・コンポーザと統合する予定です。これは音波の頭部表面での反射によって発生する回折波を考慮した音波を演算することで音源位置を容易に把握できる音を演算する技術です。バイノーラル録音を行わずに演算だけで同一の効果を実現する事に対応しています。現在、Excel VBA程度で実行できるアルゴリズムを開発済みです。 |
|
■■■記載日2011年8月12日■■■09:21頃記載 【Web シンセサイザ/ボーカロイドを一から製作してみた】(第1次試作) 前はあんなに苦労していたのに、結構あっさりとカーネル(Kernel)の試作が完了してしまった。シンセサイザとボーカロイドの発声(なんちゃって初音ミク)と歌唱のコーディングを行い、取り敢えず、Google Chrome12, Mozilla FireFox5, Apple Safari5.1で動作する シンセサイザ/ボーカロイドのカーネルを製作してみた。 【Web Vocaloid】 【ロボティックな初音ミク風スピーチのサンプル】 ●『なんちゃって初音ミク声でごあいさつ』(5~6秒の短いスピーチならすぐ) ☆ブラウザで『ソースを表示』すれば、JavaScriptのコードを見る事ができます。 【注】現在、ブラウザ側のメモリリーク改定に伴って、文字列読込速度がフリーズする現象が出ております。(Localでは再生可能なのですが)Google Chrome, Apple Safari, Fire Foxで同じ現象がでています。Cross Domainに関するセキュリティー関連の改定が影響している可能性もあります。なので近いうちに書きなおします。 ●【Finland民謡】『Ieavan Polkka』 (ドラム、なんちゃって初音ミク声付き) ■波形データを1曲分演算(rendering)して、再生まで10秒~20秒程かかります。 ■stringや型付き変数のメモリリークの影響を受けるようだ。 何回かページを連続表示するとクラッシュする場合がある。 これはJavaScriptエンジンの問題なのでどうしようもない。 再度ブラウザを起動してください。 |
【YouTube】サンプル音 テスト結果 |
|
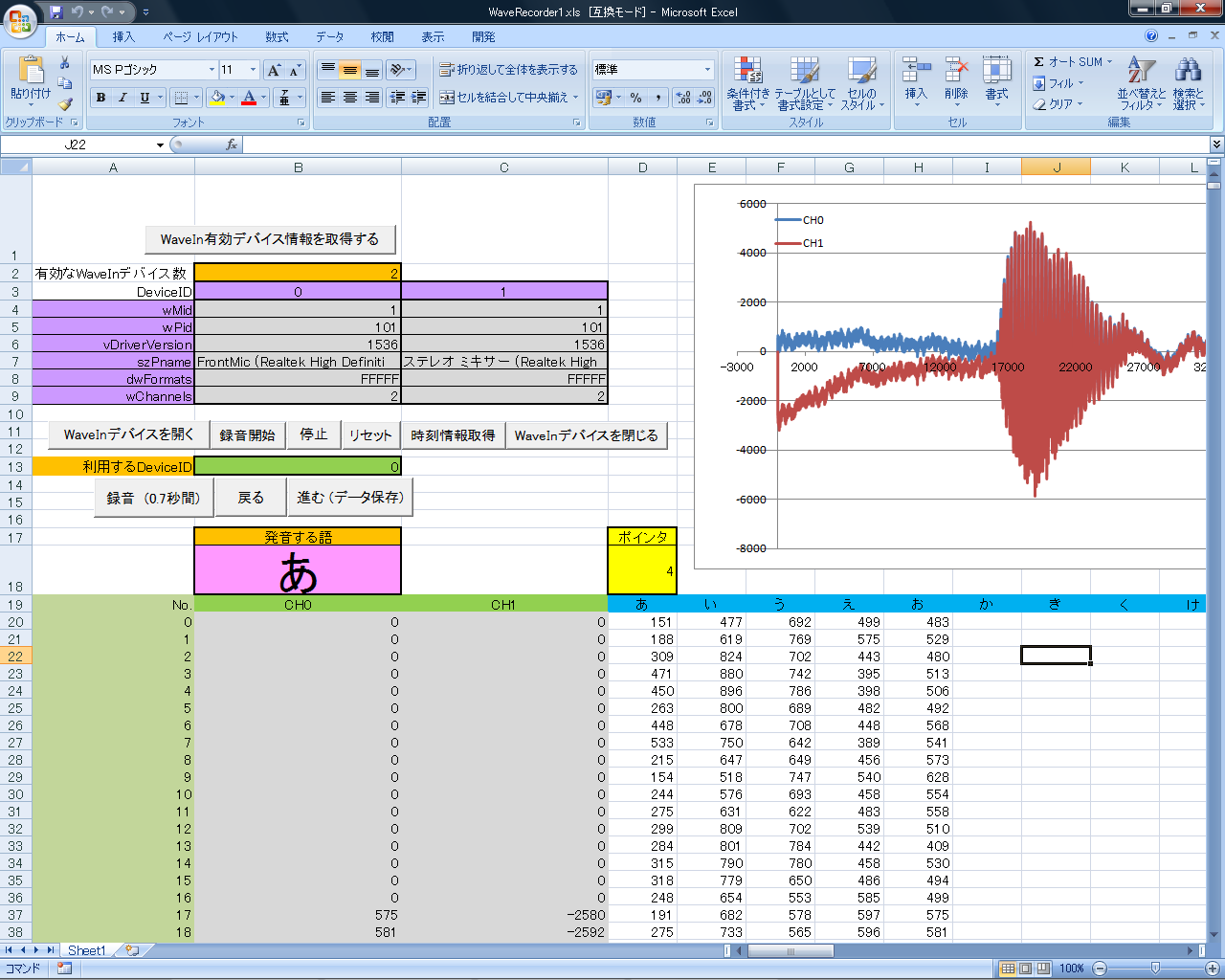
■■■記載日2011年12月04日■■■10:37頃記載 【現在の作業と今後の予定】 ●喉頭がんで声帯を失った人用のサイボーグ・インターフェース(音声再建)に応用展開中。 ハードウェアはそのうち公開の予定。まずは音声合成部分からかな? ●現在、Web Agentにさせているサンプル音のAI学習は処理が遅いので、簡単なアルゴリズムに変更予定。 ●20年程前に開発したアルゴリズムを使ってDDSアルゴリズムを改良中。 データを圧縮しつつも、より自然な発声に近づくはず。 ●毎回サウンドレコーダーやiTuneでファイル変換(.wma⇒.wav)するのが面倒になったので、 Excel VBAで録音ツール製作開始。 古い手だが、Win32APIのWaveInを使う方法。 44.1kSPS, 2ch, 16bitで音声入力をExcel Sheetに記録。学習用サンプルデータを保存。 【Excel VBAツール】Win32APIのWaveInを使った録音ツール Version 0.01 【YouTube動画】 |
【実験用サイボーグインターフェース】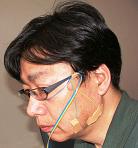  【実験用音声アドバイス機能付き浴槽心電計】 入浴者の心電図を湯水を介して無拘束で計測。虚血性心疾患の兆候や呼吸などをモニタしてアドバイスを行うエージェント・システム。  |